如何构建高可用数据处理服务以应对流量激增
在当今互联网应用场景中,流量激增是常见现象,不论是电商大促、突发新闻事件还是病毒式传播的内容,都可能瞬间带来数倍甚至数十倍的流量冲击。数据处理服务作为核心支撑系统,一旦在此时宕机,不仅影响用户体验,更可能导致严重的经济损失和品牌信誉受损。要保证数据处理服务在流量激增时不宕机,需从架构设计、资源管理、监控预警和容灾恢复等多个维度系统性地构建高可用方案。
架构层面的弹性扩展是根本保障。采用微服务架构将系统拆分为多个独立的服务模块,每个模块可根据负载单独扩缩容。结合容器化技术(如Docker)和编排工具(如Kubernetes),实现服务的快速部署与自动扩缩容。对于数据处理中的瓶颈环节,例如数据存储和计算,应采用分布式方案。数据库层面可通过读写分离、分库分表来分担压力,或选用云原生的分布式数据库(如TiDB、Aurora)。计算层面利用消息队列(如Kafka、RabbitMQ)进行异步解耦,将瞬时高峰流量缓冲为平稳的数据流,避免直接冲击后端处理服务。
资源管理与容量规划需具备前瞻性。通过历史数据和业务预测模型,预估可能的流量峰值,提前进行资源预留。利用云服务的弹性伸缩组(Auto Scaling)或负载均衡器,根据CPU使用率、网络流量等指标自动调整计算资源。设置合理的资源配额和限流机制,例如使用令牌桶或漏桶算法对API调用频率进行限制,防止单一服务过载引发雪崩效应。对于关键数据处理任务,实施优先级调度,确保高优先级任务在资源紧张时仍能正常运行。
全方位的监控与预警系统不可或缺。部署APM(应用性能管理)工具实时追踪服务响应时间、错误率和吞吐量等关键指标。结合日志分析系统(如ELK Stack)和指标监控平台(如Prometheus与Grafana),建立多级报警机制。一旦检测到异常指标,如CPU使用率持续超过阈值或错误日志激增,立即触发告警并自动执行预案,例如扩容实例或切换流量。
混沌工程与定期压力测试能暴露出系统的潜在弱点。通过模拟流量高峰、节点故障等异常场景,验证系统的容错能力和恢复速度。压力测试应覆盖从网络层到应用层的全链路,确保各组件在极限负载下仍能保持稳定。根据测试结果持续优化代码和配置,例如优化数据库查询语句、增加缓存层(如Redis)以减少重复计算。
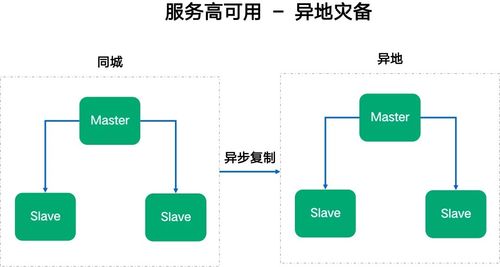
必须建立完善的容灾与故障恢复机制。采用多可用区(Availability Zone)或多地域(Region)部署,实现数据和服务的地理冗余。通过主从切换、数据备份与快速恢复方案,确保在单点故障时能迅速接管业务。制定详细的应急预案并定期演练,使团队在真实故障发生时能有序应对,最小化停机时间。
保证数据处理服务在流量激增时不宕机,是一个涵盖架构设计、资源弹性、监控预警和容灾恢复的系统工程。通过上述策略的组合实施,可显著提升服务的稳定性和韧性,从容应对各种流量挑战。
如若转载,请注明出处:http://www.bdanbao.com/product/33.html
更新时间:2026-06-19 10:58:55