软件架构中的数据同步 解决微服务间数据依赖的实践与策略
在微服务架构中,服务之间高度解耦,各自拥有独立的数据存储,以实现服务的自治性和可扩展性。这种数据分散的模式也带来了显著的数据依赖与一致性挑战。当一个服务的数据需要被其他服务频繁访问或更新时,如何高效、可靠地进行数据同步,成为了架构设计中的核心议题。
1. 数据依赖问题的核心
微服务间的数据依赖主要表现为以下几种场景:
- 数据引用:服务A需要服务B的数据才能完成业务逻辑(例如,订单服务需要用户服务的用户信息)。
- 数据聚合:一个服务需要整合多个其他服务的数据来呈现结果(例如,仪表盘服务汇总订单、库存和用户数据)。
- 数据一致性要求:某些业务操作要求跨服务的数据保持实时或最终一致性(例如,支付成功后同步更新订单状态和库存数量)。
直接的服务间API调用(如REST或gRPC)是解决依赖的常见方式,但在高并发或网络不稳定的场景下,可能导致性能瓶颈、服务耦合加剧及系统脆弱性增加。
2. 数据处理服务与数据同步策略
为有效管理数据依赖,可以引入专门的数据处理服务或采用系统性的同步策略,核心目标是在保证数据可用性与一致性的维持微服务的松耦合特性。
策略一:事件驱动架构(Event-Driven Architecture, EDA)
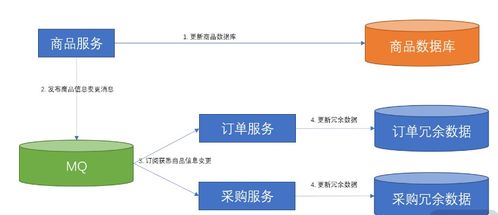
通过消息中间件(如Kafka、RabbitMQ)实现异步数据同步。
- 工作原理:当某个服务的数据发生变更时,发布一个领域事件到消息队列。其他感兴趣的服务订阅这些事件,并据此更新自己的本地数据副本或缓存。
- 优势:解耦服务间的直接调用,提高系统可扩展性和容错性;支持最终一致性。
- 挑战:需要处理消息的顺序、重复和丢失问题;可能引入数据延迟。
- 数据处理服务角色:可设计专门的事件处理服务,负责事件的标准化、路由、转换与持久化,确保数据流的可靠传递。
策略二:命令查询职责分离(CQRS)与物化视图
将数据的读写操作分离,为查询方构建专用的数据视图。
- 工作原理:写服务负责处理数据更新并发布事件;独立的查询服务(或数据处理服务)订阅事件,将数据聚合、转换后存入为查询优化的数据库(如Elasticsearch、MongoDB),直接提供数据给消费方。
- 优势:优化查询性能,避免跨服务实时Join;读写模型可独立扩展。
- 挑战:架构复杂度增加,需要维护额外的数据存储和同步逻辑。
策略三:API组合与数据聚合服务
在无法避免实时数据依赖时,通过一个专用的数据聚合服务(或API网关增强层)来统一处理数据组合。
- 工作原理:该服务作为中间层,对外提供组合后的数据接口。当收到请求时,它并行或串行调用多个底层服务的API,将结果聚合后返回。
- 优势:对前端或客户端隐藏了后端的数据分布复杂性;可集中实现缓存、降级和重试策略。
- 挑战:可能成为单点瓶颈;需要精细设计超时和错误处理机制。
策略四:分布式数据同步工具与变更数据捕获(CDC)
使用如Debezium等工具,通过数据库的日志(如MySQL的binlog)实时捕获数据变更,并流式同步到其他服务的数据存储中。
- 工作原理:CDC工具监控源数据库的日志变化,将其转换为事件流发布出去。消费服务据此更新自己的数据副本。
- 优势:对业务代码侵入小,能实现近实时的数据同步;可靠性和一致性较好。
- 挑战:需要管理数据库日志的解析和Schema变更;目标端的数据更新逻辑需自行处理。
3. 设计考量与最佳实践
- 一致性模型选择:根据业务场景权衡强一致性、最终一致性或弱一致性。多数微服务场景适合最终一致性。
- 数据所有权与界限上下文:清晰定义每个服务的数据边界,避免模糊的所有权导致同步混乱。
- 幂等性处理:在异步消息处理中,确保接收方能正确处理重复消息,避免数据错误。
- 监控与可观测性:对数据同步链路(如消息延迟、处理错误率)进行全方位监控,以便快速发现和定位问题。
- 版本管理与兼容性:当数据模型或事件格式需要变更时,需制定向前/向后兼容的策略,实现平滑升级。
4. 结论
解决微服务间的数据依赖,没有单一的“银弹”。数据处理服务 在这一生态中扮演着协调者、转换者与可靠传递者的关键角色。实践中,往往需要结合多种策略:例如,核心业务变更通过事件驱动异步同步,高频查询通过CQRS构建物化视图,而实时性要求极高的场景则辅以精心设计的API组合。成功的核心在于深入理解业务需求,在数据一致性、系统性能、开发复杂度与运维成本之间取得最佳平衡,从而构建出既健壮又灵活的分布式系统。
如若转载,请注明出处:http://www.bdanbao.com/product/54.html
更新时间:2026-06-03 06:41:22